Jak pomocí Screaming frogu najít stránky se stavovým kódem 404
Stavový kód 404 (stránka nenalezena) uživatele informuje o tom, že stránka buď nebyla nalezena, byla odstraněna nebo URL byla špatně zadána. Daný kód http protokolu dokážete vytvořit velice jednoduše, stačí za URL napsat náhodný text (https://www.alza.cz/fgfg). 404 dále můžou vzniknout například změnou struktury webu, přechodem na jiné CMS nebo úpravou kategorií.
Mít několik málo chybových stránek nevadí. Stovky nebo dokonce tisíce 404 už ano. Velké množství chyb může negativně ovlivnit vaše SEO. Naštěstí se nejedná o příliš častý jev. Horším případem je, když například změnou struktury nebo URL přicházíte o pracně budovanou návštěvnost – uživatelé se proklikávají na nefunkční stránky a nejsou přesměrováni na aktuální URL.
Seznam chybových stránek můžete získat různými způsoby. Najdete je v Google Analytics, Google Search Console nebo také prostřednictvím českého nástroje Collabim. Pokročilejší analytici zas zkoumají access logy.
V článku se však zaměřuji výhradně na Screaming frog. V domácím prostředí jsem totiž ještě nenarazil na článek, jak najít VŠECHNY čtyřistačtyřky. Může se zdát, že potřebná data získáme velice jednoduše pomocí několika kliků. Ale není tomu tak. Některé 404 jsou skryté a do problematiky je potřeba zabřednout trochu hlouběji.
Lehčí start na začátek
Na kontrolu jsem si vybral náhodný e-shop z oblasti nábytku.
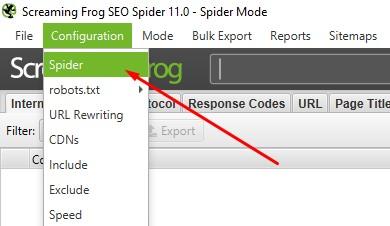
- Pokud tomu tak není, nastavíme si v záložce Mode crawlera na Spider.
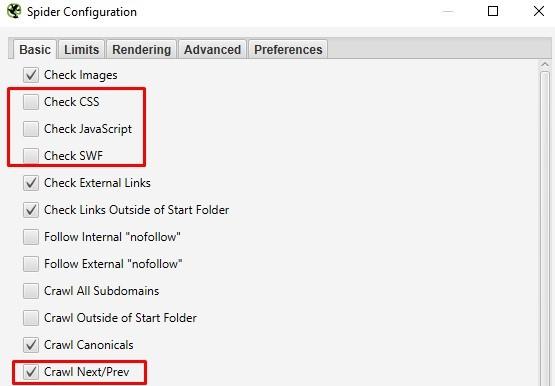
- Ručně určíme, které části webu má crawler projít. Ušetříme tím čas. Tradične vynechávám CSS, JavaScript a Flash soubory. Naopak zaškrtávám kolonku Crawl Next/Prev.
- Do vyhledávacího pole vložíme URL webové stránky, ideálně homepage a necháme Screaming frog pracovat. Čas procházení webu závisí na jeho velikosti – může se jednat o minuty, ale také o hodiny.
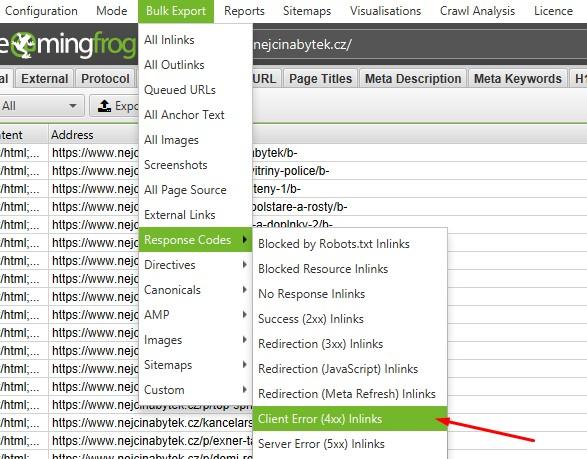
- Když nástroj projde všechny stránky a dosáhne hranice 100 %, vyexportujeme si report. Záložka Bulk export => Response codes => Client error (4xx) Inlinks.
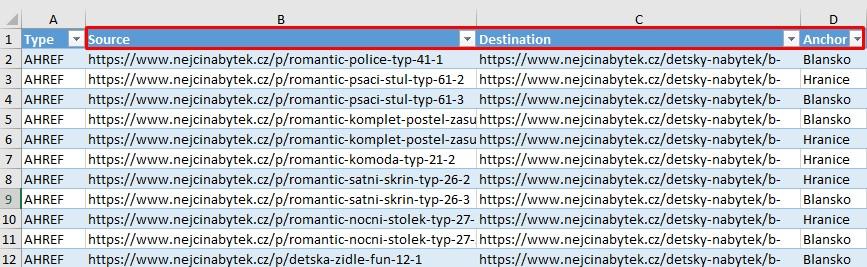
- Získal jsem potřebná data. V dokumentu jsou pro mne důležité primárně tři sloupce
• Source –kde se chybová stránka nachází, tedy zdroj.
• Destination – samotná 404, tedy kam zdrojová stránka odkazuje.
• Anchor – text odkazu (jestliže se nejedná o obrázek).
„Jde do tuhého“
Naše práce však nekončí, protože seznam ve skutečnosti neobsahuje vše, co hledáme. Další chyby se skrývají v přesměrovaných stránkách. Abychom se k nim dostali, musíme s nástrojem pracovat dál.
- Podobně jako v prvním případě si připravíme report v záložce Bulk export. Tentokrát však exportujeme seznam přesměrovaných stránek. Tedy Bulk export => Response codes => Redirection (3xx) Inlinks.
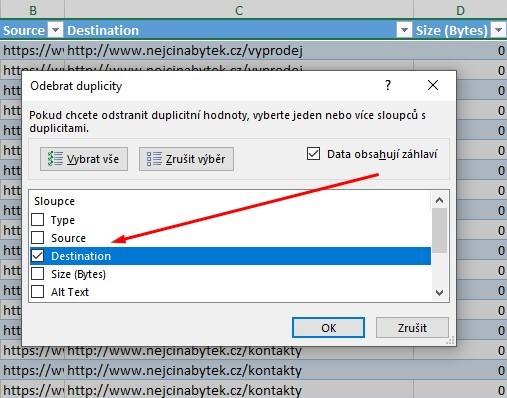
- V reportu se zaměříme na sloupec Destination. Odstraníme z něho duplicity. Ještě předtím si ale vytvořte kopii dokumentu s duplicitami. Budete ho ještě potřebovat.
- Seznam získaných URL necháme nástrojem procrawlovat.
• Mód nastavíme na List.
• Crawler upravíme tak, aby procházel přesměrování: Configuration => Spider => záložka Advanced => Always follow redirects.
• URL vložíme ručně: Upload => Enter manually…
- Vyexportujeme si report: Reports => Redirect and Canonical Chains.
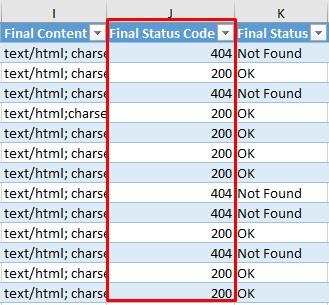
- V získaném dokumentu nás zajímá sloupec Final Status Code, tedy finální stavový kód, který URL po přesměrování má. Vidíme, že v seznamu se nacházejí stavové kódy 404. Našli jsme URL, které jsou přesměrované na chybovou stránku.
- Nalezené URL ještě musíme napárovat k jejich zdroji. V záložce Final Status Code si vyfiltrujeme jen 404. A zaměříme se na sloupec Address. POZOR, ne Final Address.
- Zkopírujeme si URL ze sloupce Address a vyhledáme jí ve vytvořené kopii dokumentu s duplicitami Redirection (3xx) Inlinks. Hledáme zdroj (Source), tedy kde se chybová stránka nachází.
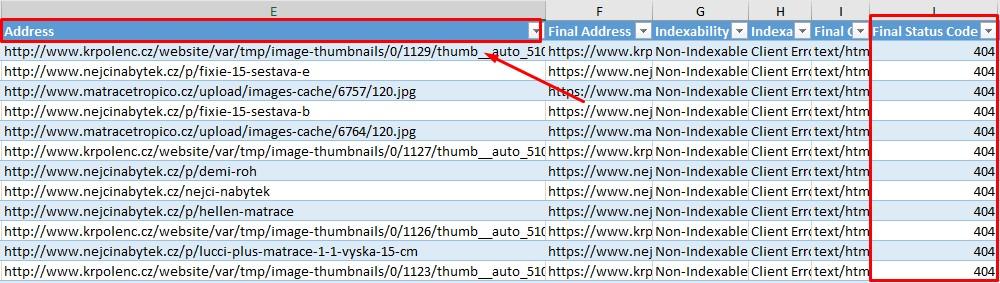
- POZOR, zdrojů bude většinou víc. Na jednu URL se stavovým kódem 404 často odkazuje vícero stránek.
- Stránky spolu napárujeme a přidáme do již získaného Excel dokumentu ze Screaming frogu.
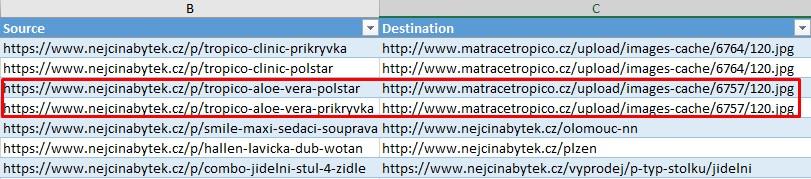
Fáze získávání dat je ukončena. Ze Screaming frogu jsme získali všechny 404, které je tento užitečný nástroj schopný najít. Následuje fáze „Co s tím?“.
Obecně chceme většinou URL přesměrovat na relevantní náhradu. Může se jednat o příbuzný produkt nebo nadřazenou kategorií. Některé 404 řešit nemusíme, například když návštěvnost již delší dobu dosahuje nulové hodnoty (zjistíme v GA), nebo když se nejedná o důležitou stránku a neexistuje její alternativa.
Je také potřeba odlišovat interní a externí chybové stránky. V případě, že odkazujete na cizí stránku, danou URL neovlivníte. Na externím webu se můžeme pokusit najít alternativní URL, avšak v případě neúspěchu nezbývá než nefunkční odkaz odstranit.
A když už se uživatel dostane na 404, stránka by ho neměla odradit, naopak, musí ho navést na správnou cestu a vysvětlit mu, co se stalo. Ideálně nějakou vtipnou formou, hlavně aby váš web neopustil a našel to, co hledal.

404 máte vyřešené? Rádi pomůžeme i s jinými SEO problémy.

Vybrané příspěvky
Sdílíme své
know-how
Inspirujte se články našich specialistů nejen z oblastí UX, SEO a marketingu...
